June 24, 2025
Unleashing Contextual Intelligence in Moodle: A Deep Dive into OpenSearch RAG with AWS Bedrock
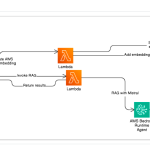
Traditional keyword-based search falls short when learners or educators seek specific knowledge across a vast Learning Management System (LMS) like […]
