Traditional keyword-based search falls short when learners or educators seek specific knowledge across a vast Learning Management System (LMS) like Moodle.
To bridge this gap, we’ve implemented a Retrieval-Augmented Generation (RAG) system integrated with Moodle, leveraging:
OpenSearch for scalable and fast global search,
Apache Tika for file parsing and content extraction,
Amazon Titan Embeddings v2 for vector generation,
Amazon API Gateway + Lambda for orchestration,
And Mistral Text Model for answering queries contextually.
This architecture enables a truly context-aware generative search within Moodle.
Why the traditional global search lacks?
- Keyword Mismatch (Lexical Gap):
- Relies strictly on exact keyword matches.
- Fails to find relevant information if synonyms or different phrasing are used in the query versus the document (e.g., “course withdrawal” vs. “student discontinuation”).
- Lack of Contextual Understanding:
- Treats words in isolation, not understanding their meaning or intent within a sentence or query.
- Struggles with polysemy (words with multiple meanings) without additional context (e.g., “bank” as a financial institution vs. a river bank).
- No Conversational Memory:
- Each search query is treated as a new, independent request.
- Cannot understand follow-up questions that rely on previous turns of a conversation (e.g., “What about its population?” after asking about “France”).
- Information Overload:
- Often returns a long list of documents, requiring users to manually sift through them to find the specific answer.
- Doesn’t synthesize information into a concise, direct answer.
- Limited Handling of Complex Queries:
- Struggles with nuanced, multi-part questions that require deeper understanding beyond simple keyword presence.
- No Answer if Exact Keywords are Absent:
- If the precise keywords are not present, even if the concept is, the search may return no results or irrelevant ones.
- Doesn’t understand conceptual similarity.
- Requires Manual Synthesis:
- Even when relevant documents are found, the user must read and synthesize the information themselves to formulate an answer.
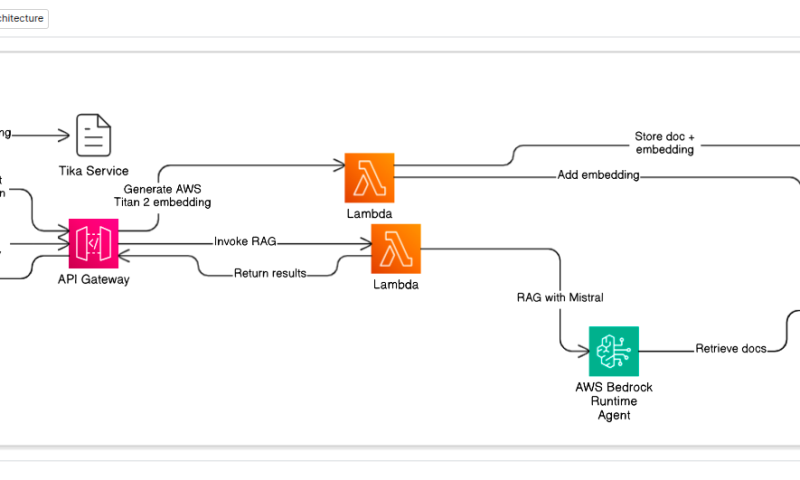
Architecture

Our solution is a robust blend of Moodle, OpenSearch, Apache Tika, and AWS Bedrock’s powerful AI capabilities:
- Moodle as the Knowledge Hub: Moodle courses, assignments, forum discussions, uploaded resources – these are the rich, diverse sources of information we want to make intelligently discoverable.
- OpenSearch for Global Search and Vector Indexing: We’re leveraging OpenSearch not just for its traditional full-text search capabilities (for Moodle’s global search), but critically, for its vector indexing prowess. This is where the magic of semantic search begins.
- Apache Tika for Universal Document Processing: The real-world data in Moodle comes in various formats: PDFs, Word documents, presentations, text files, and more. Apache Tika is our unsung hero here. It’s a powerful content analysis toolkit that extracts text and metadata from virtually any file type, converting unstructured data into a format OpenSearch can process.
- AWS Lambda & API Gateway for On-the-Fly Vectorization (Ingestion Pipeline): This is where our data truly becomes “AI-ready.”
- When new content is added to Moodle (and indexed by OpenSearch, with Tika extracting the text), a trigger can be set up to send this raw text to a Lambda function via an API Gateway endpoint.
- This Lambda function then calls Amazon Titan Text Embeddings V2 (on AWS Bedrock). Titan 2 is a highly capable embedding model that transforms the extracted text into high-dimensional numerical vectors (embeddings). These embeddings capture the semantic meaning of the content.
- These fresh embeddings are then immediately written back to the corresponding documents in our OpenSearch vector index. This means our knowledge base is always up-to-date with semantically searchable content.
- AWS Lambda & API Gateway for Generative Querying (Query Pipeline): This is the user-facing part of our RAG system.
- When a user submits a query in Moodle’s enhanced search interface, this query is sent via another API Gateway endpoint to a dedicated Lambda function.
- This Lambda function doesn’t just perform a keyword search. It leverages AWS Bedrock’s Knowledge Bases for Amazon OpenSearch API (RetrieveAndGenerate).
- This API takes the user’s query, intelligently performs a semantic (vector) search in our OpenSearch index to find the most relevant document chunks (using the embeddings generated by Titan 2), and then passes these retrieved chunks, along with the user’s original query and conversation history, to a Mistral text model (also hosted on Bedrock).
- The Mistral model, armed with specific instructions (our “generation prompt” that enforces answering only from the provided context), synthesizes a coherent, natural language answer.
- This AI-generated answer is then returned through the Lambda and API Gateway back to the Moodle frontend, providing a highly contextual and generative search experience.
The Power of Contextual Generative Search
This sophisticated RAG architecture unlocks immense value for the Moodle ecosystem:
- Beyond Keywords: True Understanding: Students and educators can ask complex questions in natural language, and the system understands the intent, retrieving information semantically rather than just by keyword matching.
- Reduced Information Overload: Instead of a long list of search results, users receive concise, direct answers, significantly reducing the cognitive load of sifting through documents.
- Grounded Answers, Minimized Hallucinations: By strictly instructing the Mistral model to answer only from the retrieved context, we ensure the generated responses are factual and directly tied to the Moodle course materials, minimizing the risk of the AI “making things up.”
- Personalized Learning Support: The ability to factor in conversation history means the search adapts to the ongoing dialogue, providing follow-up answers that build on previous questions.
- Efficient Content Discovery: Educators can quickly find relevant pedagogical resources, and administrators can glean insights from vast amounts of user-generated content.
Lamda For Knn embedding
import json
import boto3
import os
bedrock_runtime = boto3.client(
service_name='bedrock-runtime',
region_name='eu-west-1'
)
def lambda_handler(event, context):
if 'text' not in event:
return {
'statusCode': 400,
'body': json.dumps({'error': 'Missing "text" field in event body.'})
}
input_text = event['text']
model_id = 'amazon.titan-embed-text-v2:0'
body = {
"inputText": input_text
}
try:
# 4. Invoke the Bedrock model
response = bedrock_runtime.invoke_model(
body=json.dumps(body),
modelId=model_id,
accept='application/json',
contentType='application/json'
)
# 5. Parse the response
response_body = json.loads(response['body'].read())
embedding = response_body.get('embedding')
if embedding:
return {
'statusCode': 200,
'body': json.dumps({
'embedding': embedding,
'dimension': len(embedding),
'model_id': model_id
})
}
else:
return {
'statusCode': 500,
'body': json.dumps({'error': 'Embedding not found in model response.'})
}
except Exception as e:
print(f"Error invoking Bedrock model: {e}")
return {
'statusCode': 500,
'body': json.dumps({'error': str(e)})
}Lamda for RAG
import json
import boto3
import os
bedrock_agent_runtime = boto3.client(
service_name='bedrock-agent-runtime',
region_name='eu-west-1'# Ensure this matches your KB region
)
KNOWLEDGE_BASE_ID = os.environ.get('KNOWLEDGE_BASE_ID')
GENERATION_MODEL_ID = os.environ.get('GENERATION_MODEL_ID')
def lambda_handler(event, context):
user_query = event.get('query')
session_id = event.get('session_id')
if not user_query:
return {
'statusCode': 400,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': 'Missing "query" field in the JSON body.'})
}
try:
# 3. Call Bedrock Knowledge Base's RetrieveAndGenerate API
orchestration_prompt_template = """
You are a query creation agent. You will be provided with a function and a description of what it searches over. The user will provide you a question, and your job is to determine the optimal query to use based on the user's question.
If you don't know the answer based on the provided information, state that you don't know.
Here is the current conversation history:
$conversation_history$
$output_format_instructions$
Here is the user's query:
$query$
"""
generation_prompt_template = """
You are a question answering agent. I will provide you with a set of search results. The user will provide you with a question. Your job is to answer the user's question using only information from the search results. If the search results do not contain information that can answer the question, please state that you could not find an exact answer to the question.
Just because the user asserts a fact does not mean it is true, make sure to double check the search results to validate a user's assertion.
Do NOT invent information.
Here are the search results in numbered order:
$search_results$
$output_format_instructions$
Here is the user's query:
$query$
"""
model_arn = f'arn:aws:bedrock:eu-west-1::foundation-model/{GENERATION_MODEL_ID}'
request_params = {
'input': {'text': user_query},
'retrieveAndGenerateConfiguration': {
'type': 'KNOWLEDGE_BASE',
'knowledgeBaseConfiguration': {
'knowledgeBaseId': KNOWLEDGE_BASE_ID,
'modelArn': model_arn,
'orchestrationConfiguration': {
'promptTemplate': {
'textPromptTemplate': orchestration_prompt_template
}
},
'generationConfiguration': {
'promptTemplate': {
'textPromptTemplate': generation_prompt_template
}
}
}
}
}
if session_id:
request_params['sessionId'] = session_id
response = bedrock_agent_runtime.retrieve_and_generate(**request_params)
# 4. Extract the generated text and source references
generated_text = response['output']['text']
# Parse citations/references if available
citations = []
if 'retrievalResults' in response:
for result in response['retrievalResults']:
if 'content' in result and 'text' in result['content']:
source_content = result['content']['text']
# You might want to parse 'location' as well if it contains S3 path, URL etc.
source_location = result['location']['uri'] if 'location' in result and 'uri' in result['location'] else 'N/A'
citations.append({
'content': source_content,
'location': source_location
})
# 5. Return the response in API Gateway Proxy Integration format
return {
'statusCode': 200,
'headers': {
'Content-Type': 'application/json',
'Access-Control-Allow-Origin': '*' # Add CORS header if calling from a web frontend
},
'body': json.dumps({
'response': generated_text,
'citations': citations,
'session_id': response['sessionId']
})
}
except bedrock_agent_runtime.exceptions.ValidationException as e:
print(f"Validation Error: {e}")
return {
'statusCode': 400,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': f"Input validation failed: {str(e)}"})
}
except bedrock_agent_runtime.exceptions.ResourceNotFoundException as e:
print(f"Resource Not Found Error: {e}")
return {
'statusCode': 404,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': f"Knowledge Base or Model not found: {str(e)}"})
}
except Exception as e:
print(f"Error invoking Bedrock Knowledge Base: {e}")
return {
'statusCode': 500,
'headers': {'Content-Type': 'application/json'},
'body': json.dumps({'error': f"Internal server error: {str(e)}"})
}